
Proof That Deepseek Ai Is precisely What You're Searching for
페이지 정보

본문
The model uses a way often known as reasoning - just like OpenAI's o1 model. The technique is known as Group Relative Policy Optimization and makes it doable to refine AI models - even with out utilizing data provided by humans. DeepSeek was able to prepare the mannequin utilizing a data middle of Nvidia H800 GPUs in just round two months - GPUs that Chinese companies have been not too long ago restricted by the U.S. The open-supply model was first released in December when the corporate said it took solely two months and less than $6 million to create. Just every week ago - on January 20, 2025 - Chinese AI startup Deepseek Online chat unleashed a brand new, open-source AI model known as R1 that may need initially been mistaken for one of many ever-rising lots of almost interchangeable rivals which have sprung up since OpenAI debuted ChatGPT (powered by its personal GPT-3.5 model, initially) more than two years in the past. However, none of those applied sciences are new; they have been already carried out in earlier DeepSeek fashions. The analysis on AI models for mathematics that Stefan cited could have laid many important constructing blocks for the code, which R1 will even have used to automatically evaluate its answers. When requested about DeepSeek’s affect on Meta’s AI spending throughout its first-quarter earnings call, CEO Mark Zuckerberg mentioned spending on AI infrastructure will proceed to be a "strategic advantage" for Meta.
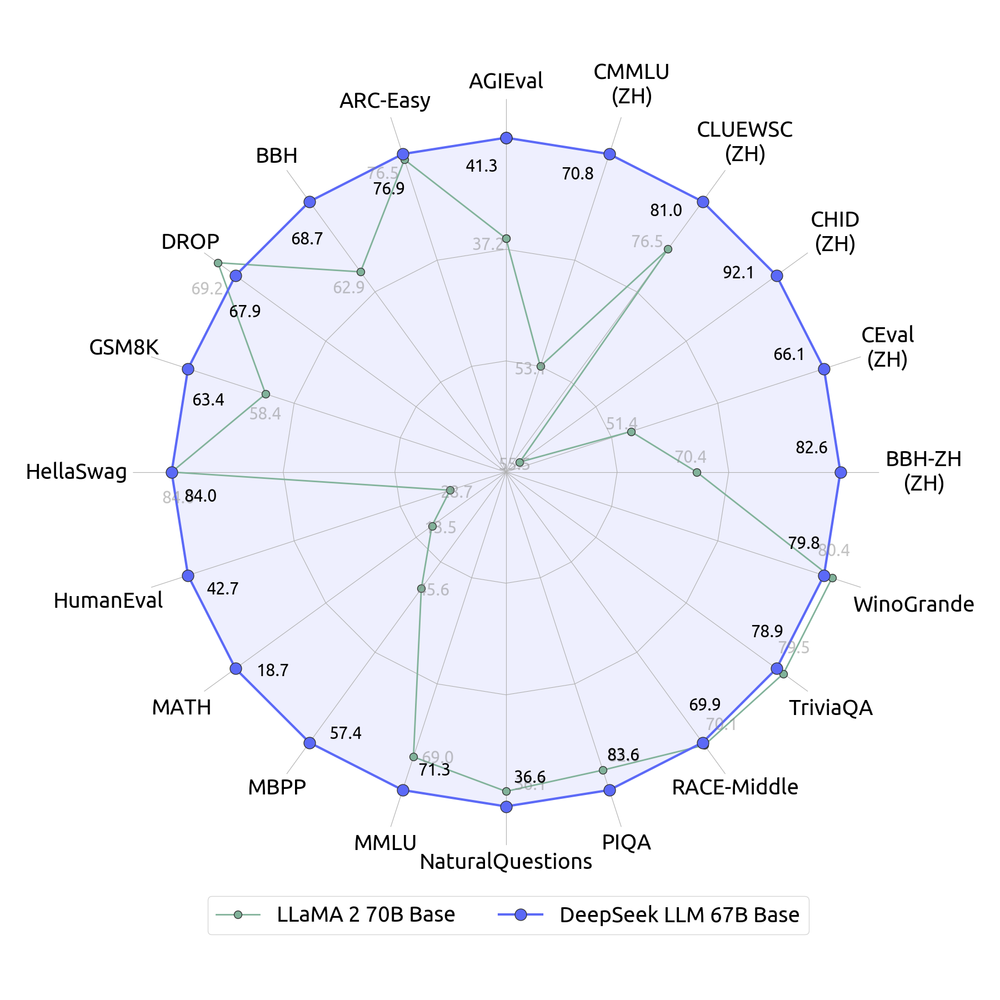 Bruce Keith, Co-founder & CEO of Bengaluru-based AI funding firm InvestorAi, believes DeepSeek’s success has bolstered the importance of smart engineering over sheer computing energy. "What DeepSeek has executed is shown what good engineering can do and reminded everyone that the race isn't gained after the first lap," he says. At the top of January, the Chinese startup DeepSeek printed a mannequin for synthetic intelligence called R1 - and sent shockwaves through AI world. This is much like the human thought process, which is why these steps are known as chains of thought. The model uses numerous intermediate steps and outputs characters that are not intended for the person. This permits OpenAI to entry Reddit's Data API, providing real-time, structured content to enhance AI instruments and consumer engagement with Reddit communities. We must be talking by way of these problems, discovering methods to mitigate them and helping folks learn the way to use these tools responsibly in ways where the constructive applications outweigh the negative. Catastrophic rounding errors due to this fact had to be prevented on the technique to discovering an answer. Despite restrictions, Chinese firms like DeepSeek v3 are discovering innovative methods to compete globally.
Bruce Keith, Co-founder & CEO of Bengaluru-based AI funding firm InvestorAi, believes DeepSeek’s success has bolstered the importance of smart engineering over sheer computing energy. "What DeepSeek has executed is shown what good engineering can do and reminded everyone that the race isn't gained after the first lap," he says. At the top of January, the Chinese startup DeepSeek printed a mannequin for synthetic intelligence called R1 - and sent shockwaves through AI world. This is much like the human thought process, which is why these steps are known as chains of thought. The model uses numerous intermediate steps and outputs characters that are not intended for the person. This permits OpenAI to entry Reddit's Data API, providing real-time, structured content to enhance AI instruments and consumer engagement with Reddit communities. We must be talking by way of these problems, discovering methods to mitigate them and helping folks learn the way to use these tools responsibly in ways where the constructive applications outweigh the negative. Catastrophic rounding errors due to this fact had to be prevented on the technique to discovering an answer. Despite restrictions, Chinese firms like DeepSeek v3 are discovering innovative methods to compete globally.
How might Deepseek free develop its AI so quickly and price-successfully? Together together with his colleague and AI professional Jan Ebert, he explains what is so particular concerning the DeepSeek AI mannequin and what makes it totally different to previous models. The costs to train models will continue to fall with open weight fashions, particularly when accompanied by detailed technical experiences, but the tempo of diffusion is bottlenecked by the necessity for challenging reverse engineering / reproduction efforts. DeepSeek costs very little to train and is way more environment friendly. 21% of the customers who've used DeepSeek are additionally saying good things about app’s efficiency while 15% of customers are saying this about ChatGPT. "The key is to help businesses with good execution, agility, and a effectively-defined monetisation plan. Good engineering made it potential to practice a big model effectively, but there isn't one single outstanding characteristic. The AUC (Area Under the Curve) worth is then calculated, which is a single worth representing the performance throughout all thresholds. So when filling out a kind, I'll get halfway done and then go and take a look at footage of lovely landmarks, or cute animals.
 Will it scale back the variety of human programming gigs? Although V3 has a very large number of parameters, a comparatively small number of parameters are actively used to foretell individual phrases (tokens). Another effectivity enchancment underlying V3 is a extra efficient comparability between individual phrases (tokens). The open availability of a low-cost, low-compute mannequin opens the door to the Jevons paradox, an financial precept which states that increased effectivity results in better general consumption reasonably than a reduction. The R1 mannequin printed in January builds on V3. As far as I know, nobody else had dared to do this before, or could get this method to work with out the model imploding sooner or later during the educational course of. Its skills in this area far outweigh these of many rival models, thus making it a useful instrument for solving intricate quantitative issues. It is vital to keep experimenting, but to do it with a clear end goal on what you are fixing for. With the suitable staff and a transparent route to product-market match, these risks may be remodeled into substantial prospects," he explains.
Will it scale back the variety of human programming gigs? Although V3 has a very large number of parameters, a comparatively small number of parameters are actively used to foretell individual phrases (tokens). Another effectivity enchancment underlying V3 is a extra efficient comparability between individual phrases (tokens). The open availability of a low-cost, low-compute mannequin opens the door to the Jevons paradox, an financial precept which states that increased effectivity results in better general consumption reasonably than a reduction. The R1 mannequin printed in January builds on V3. As far as I know, nobody else had dared to do this before, or could get this method to work with out the model imploding sooner or later during the educational course of. Its skills in this area far outweigh these of many rival models, thus making it a useful instrument for solving intricate quantitative issues. It is vital to keep experimenting, but to do it with a clear end goal on what you are fixing for. With the suitable staff and a transparent route to product-market match, these risks may be remodeled into substantial prospects," he explains.
- 이전글These Are The Most Common Mistakes People Do With Paisley Hyacinth Macaw For Sale 25.02.19
- 다음글You'll Never Guess This Driving lessons Grimsby's Tricks 25.02.19
댓글목록
등록된 댓글이 없습니다.

